关键字(key word)作为MySQL语言组成部分的一个保留字,决不要用关键字命名要给表或列
use语句并不返回任何结果。依赖于使用的客户机,显示某种形式的通知
show databases;返回可用数据库的一个列表。包含在这个列表中可能是MySQL内部使用的数据库
为了获得一个数据库内的表的列表,可用show tables;
show columns要求给出一个表名(如show columns from customers),它对每个字段返回一行,行中包含字段名、数据、类型、是否允许NULL、默认值以及其他信息。
describe语句,MySQL支持用describe作为show columns from的一种快捷方式。换句话说,describe customers;是show columns from customers的一种快捷方式。
其他show语句还有:
–>show status,用于显示广泛的服务器状态信息;
–>show create database和show create table,分别用来显示创建特定数据库或表的MySQL语句。
–>show grants,用来显示授予用户(所有用户或特定用户)的安全权限。
–>show errors和show warnings,用来显示服务错误或警告信息。
MySQL 5支持一个新的INFORMA- TION_SCHEMA命令,可用它来获得和过滤模式信息。
MySQL必知必会——MySQL简介
数据的所有存储、检索、管理和处理实际上是由数据库软件——DBMS(数据库管理系统)完成的。MySQL是一种DBMS,即它是一种数据库软件。
DBMS可分为两类:一类为基于共享文件系统的DBMS,另一类为基于客户机——服务器的DBMS
MySQL、Orancle以及Microsoft SQL Server等数据库是基于客户机——服务器的数据库。
–>服务器部分是负责所有数据访问和处理的一个软件。这个软件运行在称为数据库服务器的计算机上。与数据文件打交道的只有服务器软件。关于数据添加、删除、修改和数据更新的所有请求都是由服务器软件完成的。
–>客户机是与用户打交道的软件。
每个MySQL安装都有一个名为mysql的简单命令行使用程序。
–>命令输入在mysql>之后
–>命令用;或\g结束,换句话说,仅按Enter是不执行命令。
–>输入help或\h获得帮助,也可以输入更多的文本获得特定命令的帮助(如,输入help select获得使用SELECT语句的帮助)
–>输入quit或exit退出命令行使用程序。
MySQL Administrator(MySQL管理器)是一个图形交互客户机,用来简化MySQL服务器的管理
MySQL Administrato 提示输入服务器和登录信息(并且允许你保存服务器定义供以后选择),然后显示允许选择不同视图的图标。其中:
–>Server Information(服务器信息)显示客户机和被连接的服务器的状态和版本信息;
–>Service Control(服务控制)允许停止和起点MySQL以及指定服务器特性。
–>User Administration(用户管理) 用来定义MySQL用户、登录和权限。
–>Catalogs(目录) 列出可用的数据库并允许创建数据库和表。
MySQL Query Browser为一个图形交互客户机,用来编写和执行 MySQL命令。
MySQL Query Browser要求输入服务器和登录信息,然后显示应用界面。注意下面几点:
–>输入MySQL命令到屏幕顶上的窗口中。在输入语句后,单击Execute按钮把它提交给MySQL处理。
–>结果(如果有)显示在屏幕左边的大区域网格中。
–>多条语句和结果显示在它们自己的标签中,并且允许快速切换。
–>屏幕右边是一个标签,它列出所有可能的数据源(这里称为大纲),展开任一数据源查看它的表,展开任一表查看它的列。
–>可以选择表和列让MySQL Query Browser为你编写MySQL语句
–>Schemata(大纲)标签的右边是一个History(历史)标签,它保存MySQL语句的执行历史。在需要测试不同版本的MySQL语句时,它非常有用。
–>关于MySQL语法、函数等的帮助可在屏幕右下角得到。
MySQL必知必会——了解SQL
数据库(database): 保存有组织的数据的容器(通常是一个文件或一组文件)。
数据库软件应称为DBMS(数据库管理系统)
数据库是通过DBMS创建和操纵的容器。
表(table): 某种特定类型数据的结构化清单,存储在表中的数据是一种类型的数据或一个清单。
数据库中的每个表都有一个名字,用来标识自己。此名字是唯一的。
模式(schema): 关于数据库和表的布局及特性的信息,用来描述数据库中特定的表以及整个数据库(和其中表的关系)。
表由列组成。列中存储着表中某部分的信息。
->列(column) 表中的一个字段。所有表都是由一个或多个列组成的。
数据类型(datatype) 所容许的数据的类型。每个表列都有相 应的数据类型,它限制(或容许)该列中存储的数据。
->数据类型限制可存储在列中的数据种类(例如,防止在数值字段中 录入字符值)。数据类型还帮助正确地排序数据,并在优化磁盘使用方面 起重要的作用。
行(row) 表中的一个记录。
->表中的数据是按行存储的,所保存的每个记录存储在自己的行内。
主键(primary key)一列(或一组列),其值能够唯一区分表中每个行。
唯一标识表中每行的这个列(或这组列)称为主键。
表中的任何列都可以作为主键,只要它满足以下条件:
->任意两行都不具有相同的主键值;
->每个行都必须具有一个主键值(主键列不允许NULL值) 。
SQL(发音为字母S-Q-L或sequel)是结构化查询语言(Structured Query Language)的缩写。SQL是一种专门用来与数据库通信的语言。
SQL优点:
->SQL不是某个特定数据库供应商专有的语言。几乎所有重要的 DBMS都支持SQL,所以,学习此语言使你几乎能与所有数据库 打交道。
-> SQL简单易学。它的语句全都是由描述性很强的英语单词组成, 而且这些单词的数目不多。
->SQL尽管看上去很简单,但它实际上是一种强有力的语言,灵活 使用其语言元素,可以进行非常复杂和高级的数据库操作。
鸟哥私房菜——Linux文件与目录管理笔记
目录与路径
首先还是强调一下什么是绝对路径什么是相对路径:
绝对路径:一定是由根目录(/)写起的。
相对路径:不是由根目录写起的路径就是相对路径。
然后有一些特殊的目录需要努力记下来:
. :代表此层目录
..:代表上一个目录
-:代表前一个工作目录
~:代表目前使用者身份所在的目录
~account:代表account这个使用者的家目录(account代表账号的名称)
然后需要注意下的就是在所有目录下面都会存在两个目录,分别是“.”与”..”它们各自代表此层与上层目录的意思。另外在根目录下它的上一层(..)与根目录自己(.)是同一个目录,如下所示: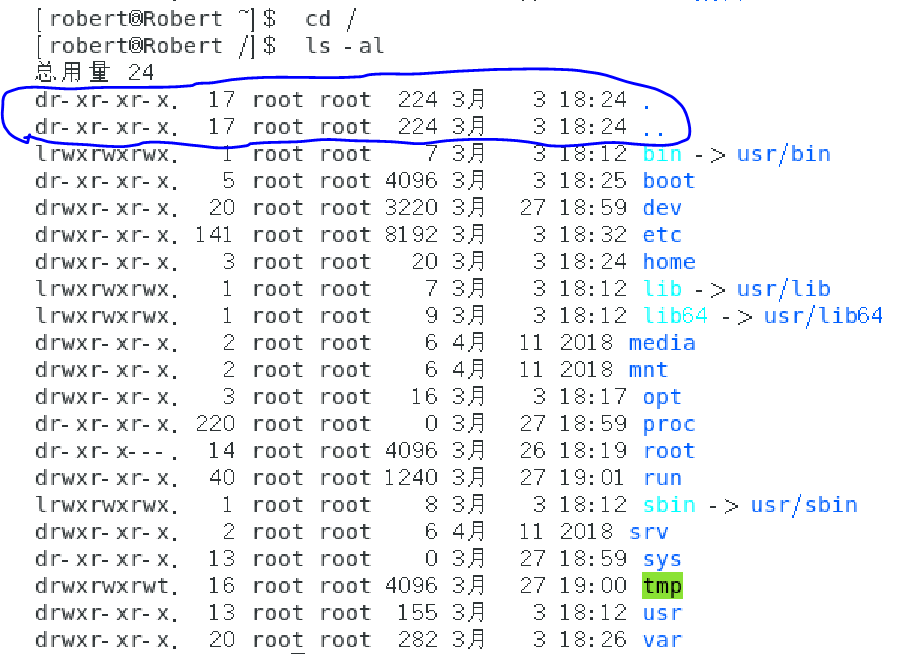
几个常见的处理目录的命令:
cd:切换目录
pwd(Print Working Directory):显示当前目录
·选项与参数(部分)
-P:显示出真正的路径,而非使用链接(link)路径
mkdir:建立一个新目录
·选项与参数(部分)
-m:设置文件的权限。直接设置,不使用默认的
-p:将所需要的目录递归创建
rmdir:删除一个空目录。需要注意的是被删除的目录里面一定不能存在其他目录或文件,也就是所谓的空目录。如果一定要删除一个非空目录可以使用[rm -r 文件名]
·选项与参数
-p:连同上层“空的目录一起删除”
cd(Change Directory):切换工作目录。需要注意的是目录名称与cd命令之间有一个空格
文件与目录管理
ls:文件与目录的查看。默认显示:非隐藏文件的文件名、以文件名进行排序及文件名代表颜色。效果如下所示:
·选项与参数(部分)
-a:全部文件,连同隐藏文件(开头为.的文件)一起列出来
-d:仅列出目录本身,而不是列出目录内的文件数据
-l:详细信息显示,包含文件的属性与权限等数据
cp:复制文件
mv:移动目录与文件,同时也可以拿来做重命名
rm:删除文件或目录
basename:获取路径的文件名
dirname:获取路径的目录名
文件内容的查看
cat:由第一行开始显示文件的内容
tac:从最后一行开始显示
nl:显示的时候,同时输出行号
more:一页一页的显示文件内容
less:与more类似,但是比more更好的是,可以往前翻页
head:只看前面几行
tail:只看后面几行
od:以二进制方式读取文件内容
|:管道符号。前面的命令所输出的信息,通过管道交由后续的命令继续使用
touch:修改文件时间或创建新文件。
这里需要了解下修改时间,状态时间,读取时间,这三个时间的意思。
·修改时间(modification time,mtime):
当该文件的【内容数据】变更时,就是更新这个时间,内容数据指的是文件的内容,而不是文件的属性或是权限。
·状态时间(status time, ctime):
当该文件的【状态status】改变时,就会更新这个时间。例如权限或是属性被更改了,都会更新这个时间
·读取时间(access time,atime):
当【该文件的内容被读取】时,就是更新这个读取时间。
文件与目录的默认权限与隐藏权限
umask:指定用户在建立文件或目录时的权限默认值
chattr:配置文件隐藏属性。注意该命令只能在ext2,ext3,ext4的Linux传统文件系统上面完整生效,其他文件系统无法完整支持该命令,例如xfs系统仅支持部分参数
lsattr:显示文件隐藏属性
SUID:
该权限仅对二进制程序有效,不能够用在shell脚本上面
执行者对该程序需要具有X的可执行权限
本权限在执行改程序的过程中有效
执行者将具有该程序拥有者的权限
SGID:
该权限对二进制程序有用
程序执行者对于改程序来说,需要具备X的权限
执行者在执行的过程中将会获得该程序用户组的支持
SBIT:目前只针对目录,对于文件已经没有效果了
当用户对于此目录具有w,x权限,即具有写入的权限
当用户在该目录下建立文件或目录,仅由自己与root才有权力删除该文件
file:观察文件类型
命令与文件的查找
which:根据【PATH】环境变量所规范的路径,去查找【执行文件】的文件名
whereis:查找系统中某些特定目录下面的文件
locate:利用数据库来查找文件名
find:可以加入许多选项来直接查询文件系统,以获得自己想要知道的文件
权限与命令间的关系
一. 让用户能进入某目录成为可工作目录的基本权限:
可使用的命令:如cd等变换工作目录的命令
目录所需权限:用户对这个目录至少需要具有x的权限
额外需求:如果需要在这个目录内利用ls查看文件名,则用户对此目录还需要r的权限
二.用户在某个目录内读取一个文件的基本权限:
可使用的命令:如cat,more,less等
目录所需权限:至少需要x权限
文件所需权限:至少需要r的权限
三.让用户可以修改一个文件的基本权限:
可使用的命令:例如nano,vi编辑器等
目录所需的权限:用户在改文件所在的目录至少需要x权限
文件所需权限:用户对该文件至少要有人r,w权限
四.让一个用户可以建立一个文件的基本权限:
目录所需权限:用户在该目录要具有w,x的权限,重点在w
五.让用户进入某目录并执行该目录下的某个命令只基本权限
目录所需权限:用户在该目录下至少要有x的权限
文件所需权限:用户在该文件至少需要有x的权限
鸟哥私房菜——第五章小结笔记
Linux的文件权限与目录配置
Linux将文件可读写的身份分为三类:执行者(owner)、所属群组(group)、其他人(others),而三种身份各有读(read)、写(write)、执行(execute)。
ls -al:查看文件命令
ls是list的意思,重点在显示文件的文件名与相关属性。选项[-al]则表示列出所有的文件详细的权限与属性(包含隐藏文件)。效果如下所示: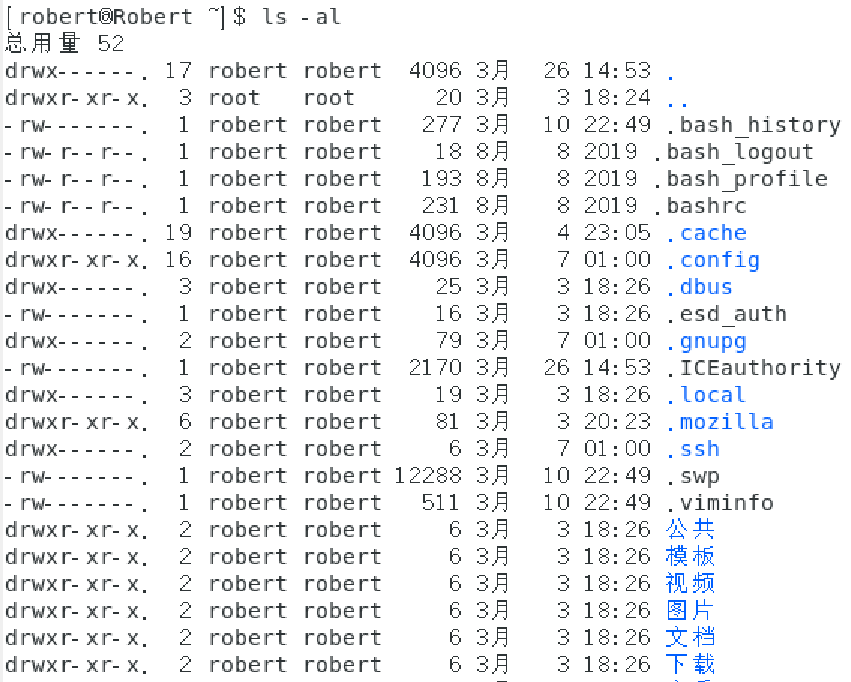
先解释下上面七个字段的意思。
·第一栏第一个字符代表这个文件是目录、文件或链接文件等:
若为[d]则是目录,例如上表第一行;
若为[-]则是文件,例如上表第三行;
若为[l]则是链接文件(link file)
若为[b]则是设备文件里面的可供存粹的周边设备(可按快随机读写的设备)
若为[c]则表示为设备文件里面的串行端口设备,例如键盘、鼠标等一次性读取设备
接下来的字符中,以三个为一组,且均为【rwx】的三个参数的组后。其中[r]代表可读(read)、
[w]代表可写(write)、 [x]代表代表可执行[execute]。需要注意的是这个三个权限的位置不会改变,如果没有就会出现减号[-]。
第一组为文件拥有者可具备的权限,第二组为加入此用户组之账号的权限,第三组为非本人且没有加入本用户组的其他账号的权限;
·第二栏表示有多少文件名链接到此节点
·第三栏表示这个文件(或目录)的拥有者账号
·第四栏表示这个文件的所属用户组
·第五栏表示这个文件的容量大小,默认单位是Bytes
·第六栏表示这个文件的创建日期或是最近的修改日期
·第七栏表示文件名。需要注意的是如果文件名之前多一个【.】则表示这个文件为隐藏文件
修改文件属性与权限
chgrp:修改文件所属用户组;
chown:修改文件拥有者;
chmod:修改文件的权限,SUID、SGID、SBIT等特性
修改用户组和拥有者很简单,特别说下修改文件权限。权限设置方法有两种,分别是数字和符号。
数字类型:
Linux文件的基本权限就有9个,分别是拥有者(owner)、所属群组(group)、其他人(others)三者身份各有自己的读(read)、写(write)、执行(execute)权限。根据找这些数据,文件的权限字符为:
【-rwxrwxrwx】这个九个权限是三个三个一组。其实可以用数字来代表各个权限,对照表为:
r:4
w:2
x:1
每种身份的各自的三个权限数字是需要累加的,例如当权限是:【-rwxrwx—】数字则是:
owner=rwx=4+2+1=7
group=rwx=4+2+1=7
others=—=0+0+0=0
因此修改权限的命令chmod的语法是:
chmod [-R] xyz 文件或是目录。xzy就是数字类型的权限属性,为rwx属性数值的累加。-R表示递归修改,即连同子目录下的所有文件都会修改。
符号类型:
根据上面的了解九个权限分别是(1)user (2)group (3)others三者身份,那么就可以借由 u、g、o来代表三种身份权限。此外a代表all即全部的身份
例如设置一个文件的权限为【-rwxr-xr-x】对应的写法是:chmod u=rwx,go=rx 文件名
目录与文件的权限意义
权限对文件的重要性
r(read):可读取此文件的实际内容,如读取文本文件的文字内容等
w(write):可以编辑此、新增或是修改此文件的内容(但不含删除此文件)
x(execute):该文件具有可以被系统执行的权限
注意:Linux系统中判断某一个文件是否能被执行,是借由是否具有【x】这个权限来决定的,和文件名没有关系。
权限对目录的重要性
r(read):表示具有读取目录结构列表的权限,因此当你具有读取(r)一个目录的权限时,表示可以查询该目录下文件名数据。
w(write):表示具有改动改目录结构列表的权限。如可以新建或删除文件与目录,移动与重命名已存在的文件与目录
x(execute):代表用户能否进入改目录成功工作目录。所谓的工作目录就是你目前所再的目录。
Linux文件种类与扩展名
·常规文件(regular file):大概分为:纯文本文件,二进制文件,数据文件
·目录(directory)
·链接文件(link)
·设备与设备文件:通常分为两种:区块(block)设备文件,字符(character)设备文件
·数据接口文件(sockets)
·数据传送文件(FIFO<先进先出的缩写(first-in-first-out)>,pipe)
.sh:脚本或处理文件,因为批处理文件是使用shell写出的,因此扩展名为.sh
Z,.tar,.tar.gz,.zip,.tgz:经过打包的压缩文件,有不同的压缩软件,取其相关的扩展名
.html,.php:网页相关的文件,分别代表HTML与PHP语法的网页文件。
Linux针对文件名长度限制为:单一文件或目录的最大容许文件名为255字节,以一个ASCLL英文占用一个字节来说,则大约可达255个字符长度。若以每个汉字占用2个字节来说,最大文件名大约在128个汉字之间
Linux目录的配置
Linux目录配置的依据——FHS,阵对目录树架构定义出了三层目录下面应该放置什么数据:
/(root,根目录):与启动有关。根目录(/)所在分区应该越小越好,如此不但性能较佳,根目录所在的文件系统也较稳定
/usr(unix software resource):与软件安装/执行有关。
/var(variable):与系统运行过程有关
目录树的一些特性:
·目录树的起始点为根目录(/)
·每一个目录不止能使用本地分区的文件系统,也可以使用网络上的文件系统。例如可以通过NFS服务器挂载某特定目录
·每一个文件再次目录树中的文件名(包含完整路径)都是独一无二的。
绝对路径:由根目录(/)开始写起的文件名或目录名称
相对路径:开头不是由根目录(/)写起的文件名或目录名称。相对路径是以你当前所在路径的相对位置来表示的
. :代表当前的目录,也可以使用./来表示
.. :代表上一层目录,也可以使用../来表示
鸟哥私房菜——第四章小结笔记
前言
鸟哥的私房菜买了有快两个月了,但一直拖着没看完。自己觉得也不是个事儿,就准备这个月逼自己一把。月底看完,每天一章节。然后对每个章节写个笔记,总结下。就从第四章开始吧。
第一部分:熟悉X Window窗口管理器环境以及于对命令行模式的切换
X Window窗口管理器环境就算是Linux的图像界面,修改一些系统的设置,练练手。比如修改下分辨率啊什么的,都是一些常规操作,没什么好复习的。接下来就是从窗口管理环境切换到命令行模式了。命令行界面也叫做终端界面、Terminal或Console。Linux在默认的情况下提供了六个终端来让用户登录。切换方式为:Ctr+Alt+F1~F6。按下组合键输入用户名和密码登录进去,就可以输入命令了。
第二部分:命令行模式下命令的执行
1)概念:[robert@study ~ ]$ command [-options] parameter1 parameter2……。
1.[robert@study ~ ]$:最左边的robert表示目前用户账户,而@之后接的study是主机名,最右边的~指的是目前所在的目录,那个$就算常常说到的提示符。
2.command:表示命令的名称,如切换工作目录的命令cd等。
3.[-options]:表示可选,并不存在于实际的命令中。加入选项设置时,通常选项前会带-符号,如-h;有时候还会使用选项的完整全名,则选项前会带有–符号,如–help。
4.parameter1 parameter2:表示选项后面的参数,或是命令(command)的参数。
5.命令,选项,参数这几个东西中间以空格来区分。命令太长的时候,可以使用反斜杠(\)来转义回车键,使命令连续到下一行。
6.Linux系统中英文大小写是不一样的。
2)基础命令的操作和几个热键
ls :列出自家目录下的所有隐藏文件与相关的文件属性
date:显示日期与世时间的命令
cal:显示日历的命令
bc:计算器
[ Tab]:具有命令补齐与文件补齐的功能。接在一串命令的第一个字段后面,为命令补全;接在一串 命令的第二个字段后面, 为文件补全。若安装了Bash-completion软件,则在某些命令后面按住[Tab]键,可以进行选项/参数的补齐
[Ctr]-c:中断程序
[Ctr]-d:键盘输入结束。
[Shift]+{[Page UP]}{[Page Down]}:当某些命令的输出信息相当的长时,可以使用这个组合键进行前后翻页。
–help:命令的求助说明。
man:查询命令的用法与相关参数的说明
info:与man一样都是查询命令的用法或是文件的格式。不同的是,info是将文件数据拆成一个一个的段落,每个段落用自己的页面进行编写的,并且每个页面中还有类似网页的超链接来跳转到各个不同的页面中,每个独立的页面也被称为一个节点。
nano:超简单的文本编辑器。
who:查看目前有谁在线。
netstat -a:查看网络的联机状态。
ps -aux:查看后台执行的程序。
sync:将数据同步写入硬盘当中。
shutdown:常用的关机命令。同时reboot、halt、poweroff这三个命令也可以进行重新启动与关机的任务。
字符串匹配之PabinKarp算法
第一次写博客,不足之处还请大家指教。下面直接进入主题。
概述
字符串匹配相信大家都很熟悉,有很多种解法。比如kmp算法啊,PabinKarp算法啊,当然暴力解法也都行。
前几天看蓝桥《算法很美》的视频,里面讲到了PabinKarp算法,觉得挺好玩儿的今天我们就来浅谈一下PabinKarp算法,对自己来说也算个总结。
PabinKarp算法其实就是预处理吧。首先用类似于求进制的方法对模式串进行求值,如选一个进制数(31进制)算出它的hash值。然后对原字符串进行处理,具体的处理方法就是。从原字符串的第一个字符开始到模式串的位数,把它看成一个字符串算出它的hash值,然后和模式串的hash值进行比较,相等的话就表示这个字符串与模式串相同。之后再从第二字符开始到模式串的位数,算出这个字符串的hash值再与模式串的hash值进行比较,以此类推直至比较完整个字符串。我写的这个话是我个人对PabinKarp算法理解的一个白话,可能有小伙伴不怎么理解,举个具体例子把。
实例
原串为:abababa
模式串为:aba
首先选一个进制数就31吧,然后用求进制的方法将模式串转换成一个hash值。之后就是对原串的处理了。因为模式串大小是3,所以就从原串的第一个字符开始到第三个字符结束,也就是aba。然后同样用转模式串的方法对这个字串进行运算,算出它的hash值。把这个hash值与模式串的hash值进行比较,相等就表示这个字串与模式串相等,反之就是不等。然后再从第二个字符开始,把它看成是第一位直到第三位结束,也就是bab,算出它的hash值与模式串比较,看是否相等,之后就是从第三、第四位开始以此类推。直到原串的第六位结束,因为你从第六位开始划分,你划不出来三个,它后面只有一个字符。换句话说当你比完第从五位字符开始划分的那个字串后,你就要结束你的循环了,不能再继续下去了。我举得这个例子后,大家应该就对什么是PabinKarp算法有个大致的了解把。从写程序的方面来看,我们大致可以理解为我们要完成三件事,第一:求出模式串的hash值,第二:构建hash数组里面存放从原串的第一个字符开始到第五个字符结束的这些个字串的hash值。第三:将模式串的hash值与hash数组里面的值比较,找出相等的字串。下面我们就直接来看代码
代码
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#include <math.h>
#include <string.h>
#define Seed 31//选的k进制数
char *fun1(char *string,int left,int right);//截断字符串的方法
int fun2(char *s); //求字符串hash值的方法
int *fun(char *s,int n);//构建hash数组的方法
void match1(char *s,char *ss);//传入原串和模式串,然后依次调用函数
void match(int hash_p,int hash_s[]);//比较模式串的hash值与hash数组的值,并输出相等字串的第一个字符的下标
static count=0;//定义一个全局变量,表示hash数组的大小
int main(void) {
char *n=”abababa”;
char *m=”aba”;
match1(n,m);
return 0;
}
void match1(char *s,char *ss)
{
int hash_p=fun2(ss);
match(hash_p,fun(s,strlen(ss)));
}
void match(int hash_p,int hash_s[])
{
int i;
for(i=0;i<=count;i++)
{
if(hash_p==hash_s[i])
{
printf(“下标为:%d\n”,i);
}
}
}
//构建hash数组
int *fun(char s,int n)
{
int String;
int m=(strlen(s)-n+1);
String=(int)malloc(m sizeof(int));
if(NULL == String)
{
printf(“内存溢出. \n”);
exit(0);
}
count=strlen(s)-n+1;
String[0]=fun2(fun1(s,0,n));
int i;
int v;
for(i=n;i<strlen(s);i++)
{
int newChar=s[i];
int oChar=s[i-n];
v=(int)(String[i-n]*Seed+newChar-pow(Seed,n)*oChar)%INT_MAX;
count++;
String[i-n+1]=v;
}
return String;
}
int fun2(char s)//求字符串的hash值
{
int hash=0;
int i;
for(i=0;i<strlen(s);i++)
{
hash=Seedhash+(int)s[i];
}
return hash%INT_MAX;
}
char *fun1(char *string,int left,int right)//截子符串
{
char sc;
int string_length=strlen(string);
int real_length=((string_length-left)>=right?right:(string_length-left));
if (NULL == (sc=(char) malloc(real_length * sizeof(char))))
{
printf(“Memory overflow . \n”);
exit(0);
}
strncpy(sc,string+left,real_length);
sc[real_length]=’\0’;
return sc;