字符串基础:字符串就是一串零个或多个字符,并且以一个模式为全0的NULL字节结尾。因此,字符串所包含的字符内部不能出现NULL字节。NULL字节是字符串的终止符,但它本身不是字符串的一部分,所以字符串的长度并不包括NULL字节。
字符串的长度:字符串的长度就是它所包含的字符个数。
CUE: size_t 这个类型是在头文件stddef.h中定义的,它是一个无符号整数类型。
复制字符串:函数strcpy原型如下:
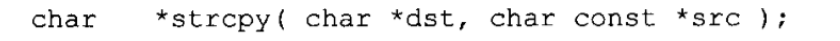
该函数把参数src字符串复制到dst参数。如果参数src和dst在内存中重叠,其结果是未定义的。参数dst必须是个字符数组或者是一个指向动态分配内存的数组的指针,不能是字符串常量。
注:必须保证目标字符数组的空间足以容纳需要复制的字符串。如果字符串比数组长,多余的字符仍被复制,它们将覆盖原型存储与数组后面的内存空间的值。
连接字符串:函数strcat原型如下:
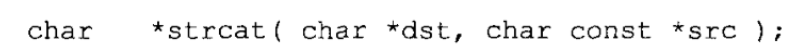
函数要求dst参数原先已经包含一个字符串(可以是空字符串)。函数找到这个字符串的末尾,并把src字符串的一份拷贝添加到这个位置。如果src和dst的位置发生重叠,其结果是未定义的。
注:同样必须保证目标字符数组剩余的空间足以保存整个源字符串。
函数的返回值:strcpy和strcat都返回它们第1个参数的一份拷贝,就是一个指向目标字符数组的指针。
字符串比较:函数strcmp原型如下:
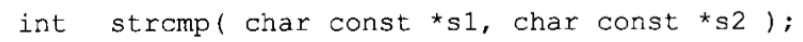
如果s1小于s2,函数返回一个小于零的值。如果s1大于s2,函数返回一个大于零的值。如果两个字符串相等,函数就返回零。
长度受限的字符串函数:函数原型如下:
 ****
****
和strcpy一样,strncpy把源字符串的字符复制到目标数组。然后,它总是正好向dst写入len个字符。如果srtlen(src)的值小于len,dst数组就用额外的NULL字节填充答len长度。如果strlen(scr)的值大于或等于len,那么只有len个字符复制到dst中。注意!它的结果将不会以NULL字节结尾。
strncat函数从src中最多复制len个字符到目标数组的后面,但strncat总是在结果字符串后面添加一个NULL字节,而且它不会像strncpy那样对目标数组用NULL字节进行填充。
strncmp函数也用于比较两个字符串,但它最多比较len个字节。其比较结果和strcmp函数一致。
查找一个字符:最容易的方法是使用strchr和sttrchr函数。原型如下:

两个函数的第2个参数是一个整数。但是,它包含了一个字符值。strchr在字符串str中查找字符ch第1次出现的位置,找到后函数返回一个指向该位置的指针。如果该字符并不存在于字符串中,函数就返回一个NULL指针。sttrchr的功能和strchr基本一致,只是它所返回的是一个指向字符串中该字符最后一次出现的位置(最右边那个)。
查找任何几个字符:函数strpbrk原型如下:
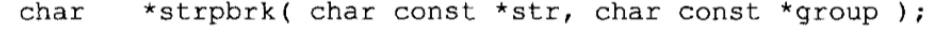
函数返回一个指向str中的第1个匹配group中任何一个字符的字符位置。如果未找到匹配,函数就返回一个NULL指针。
查找一个子串:函数strstr原型如下:
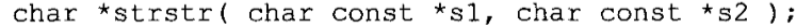
函数在s1中查找整个s2第1次出现的起始位置,并返回一个指向该位置的指针。如果s2并没有完整地出现在s1的任何地方,函数将返回一个NULL指针。如果第2个参数是一个空字符串,函数就返回s1。
查找一个字符串前缀:函数strspn和strcspn用于在字符串的起始位置对字符计数。原型如下:

group字符串指定一个或多个字符。strspn返回str起始部分匹配group中任意字符的字符数。strcspn函数和strspn函数正好相反,它对str字符串起始部分中不与group中任何字符匹配的字符进行计数。
查找标记:strtok函数从字符串中隔离各个单独的称为标记(token)的部分,并丢弃分隔符。函数原型如下:
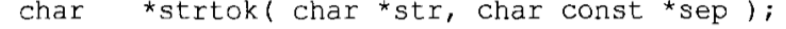
sep参数是个字符串,定义了用作分隔符的字符集合。第1参数指定一个字符串,它包含零个或多个由sep字符串中一个或多个分隔符分隔的标记。strtok找到str的下一个标记,并将其用NULL结尾,然后返回一个指向这个标记的指针。
注:当strtok函数执行任务时,它将会修改它所处理的字符串。如果字符串不能被被修改,那么就复制一份,将这份拷贝传递个strtok函数。同时,如果strtok函数的第1个参数不是NULL,函数将找到字符串的第1个标记。strtok同时将保存它在字符串中的位置。如果strtok函数的第1个参数是NULL,函数就在同一个字符串中从这个被保存的位置开始像前面一样查找下一个标记。如果字符串内不存在更多的标记,strtok函数就返回一个NULL指针。
错误信息:strerror函数把其中一个错误代码作为参数,并返回一个指向用于描述错误的字符串的指针。函数原型如下:
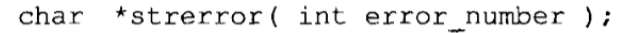
字符分类:每个分类函数接受一个包含字符值的整型参数。函数测试这个字符并返回一个整型值,表示真或假。

转换函数进行大小写字母互换。函数原型如下:

toupper函数返回对应大写,tolower函数返回其对应小写。如果函数的参数并不是一个个处于适当大小写状态的字符,函数将不修改参数直接返回。
内存操作:下列函数的操作与字符串函数类似,但这些函数能够处理任意的字节序列。原型如下:

它们在遇到NULL字节时并不会停止操作。
memcpy从src的起始位置复制length个字节到dst的内存起始位置。第3个参数指定复制值的长度(以字节计)。如果src和dst以任何形式出现重叠,它的结果是未定义的。
memmove函数的行为和memcpy差不多,只是它的源和目标操作数可以覆盖。
memcmp对两段内存的内容进行比较,这两段内存分别起始于a和b,共比较length个字节。这些值按照无符号字节逐字节进行比较,函数返回负值表示a小于b,正值表示a大于b,零表示a等于b。
注意:由于这些值是根据一串无符号字节进行比较的,所以如果函数用于比较不是单字节的数据如整数或浮点数时就可能出现不可预料的结果。
memchr函数从a的起始位置开始查找字符ch第1次出现的位置,并返回一个指向该位置的指针,它共查找length个字节。如果在这length个字节中未找到该字符,函数就返回一个NULL指针。最后memset函数把从a开始的length个字节都设置为字符值ch。
strlen函数用于计算一个字符串的长度,它返回值是一个无符号整数。













 ),可以容纳的有符号整数的范围是从-2147483648(
),可以容纳的有符号整数的范围是从-2147483648( )至2147483648(
)至2147483648( )。注意,尽管一个字包含了4个字节,它仍然只有一个地址。至于它的地址是它最左边的那个字节的位置还是最右边那个字节的位置,不同的机器有不同的规定。另一个要注意的硬件事项是边界对齐。在要求边界对齐的机器上,整型值存储的起始位置只能是某些特定的字节,通常是2或4的倍数。
)。注意,尽管一个字包含了4个字节,它仍然只有一个地址。至于它的地址是它最左边的那个字节的位置还是最右边那个字节的位置,不同的机器有不同的规定。另一个要注意的硬件事项是边界对齐。在要求边界对齐的机器上,整型值存储的起始位置只能是某些特定的字节,通常是2或4的倍数。