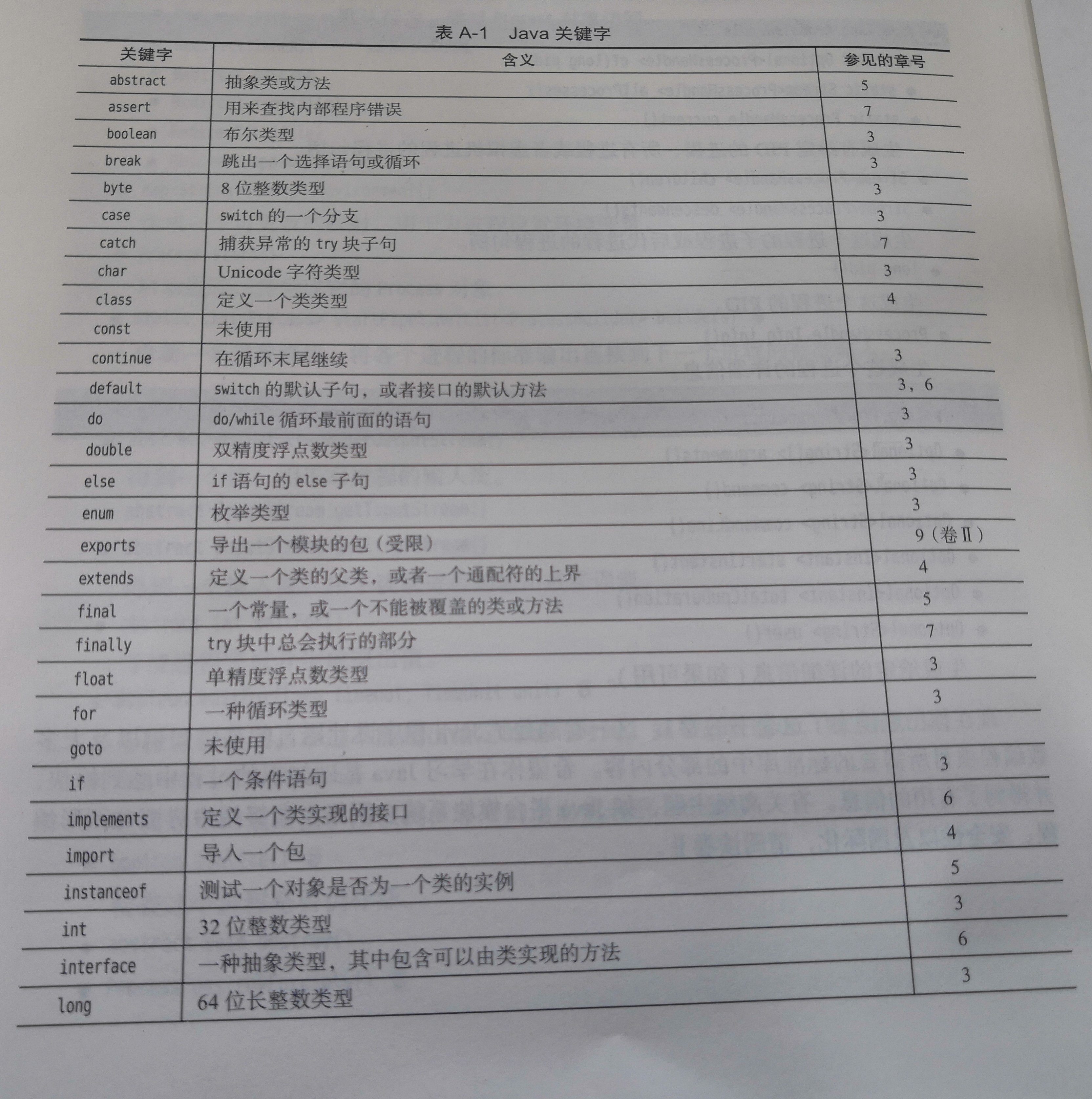
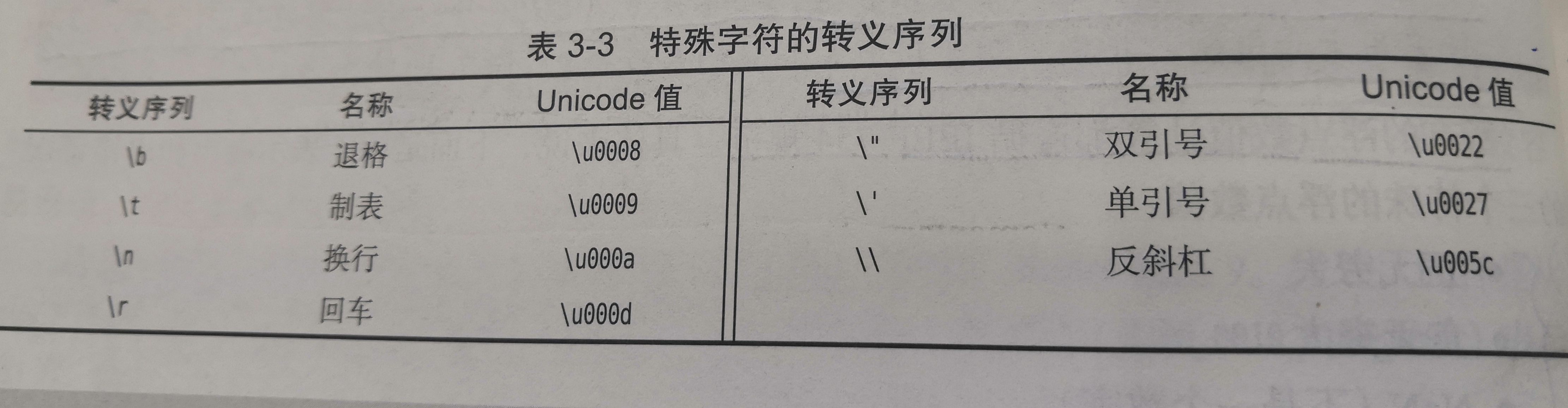
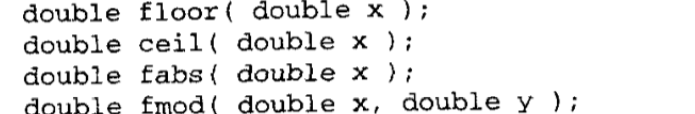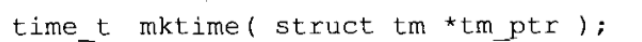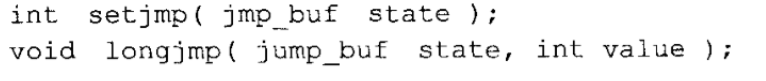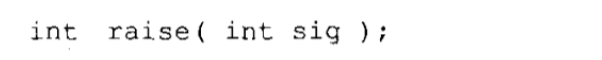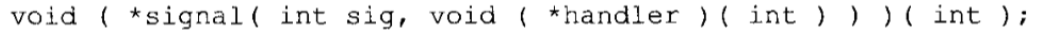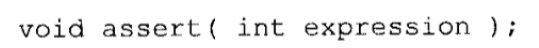ANSI C和早期 C相比的最大优点之一就是它在规范里所包含的函数库。每个ANSI编译器必须支持一组规定的函数,并具备规范所要求的接口,而且按照规定的行为工作。
错误报告:perror函数以一种简单、统一的方式报告错误。ANSI C函数库的许多函数用OS来完成某些任务,I/O函数尤其如此。标准库函数在一个外部整型变量errno(在errno.h)中保存错误代码之后就把这个信息传递给用户程序,提示操作失败的准确原因。perror函数简化向用户报告这些特定错误的过程。它的原型定义于stdio.h,如下所示:
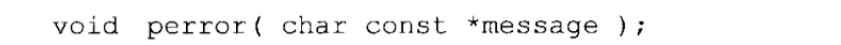
如果message不是NULL并且指向一个非空的字符串,perror函数就打印出这个字符串,后面跟一个分号和一个空格,然后打印出一条用于解释errno当前错误代码的信息。
注:只有当一个库函数失败时,errno才会被设置。当函数成功运行时,errno的值不会被修改。
终止执行:函数exit,它用于终止一个程序的执行。它的原型定义于stdlib.h。如下所示:
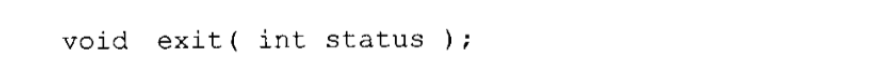
status参数返回给OS,用于提示程序是否正常完成。这个值和main函数返回的整型状态值相同。预定义符号EXIT_SUCCESS和EXIT_FAILURE分别提示程序的终止是成功还是失败。注意该函数没有返回值。当exit函数结束时,程序已经消失,所以它无处可返。
标准I/O函数库(standard I/O library)具有一组I/O函数,实现了在原先的I/O库基础上许多程序员自行添加实现的额外功能。函数库同时引进了缓存I/O的概念,提高了绝对大多数程序的效率。
ANSI I/O概念:头文件stdio.h包含了与ANSI 函数库的I/O部分有关的声明。它的名字来源于旧式的标准I/O函数库。
流:ANSI C进一步对I/O的概念进行了抽象,就C程序而言,所有的I/O操作只是简单地从程序移进或移出字节的事情。因此,这种字节流便被称为流(stream)。绝大多数流是完全缓冲,这意味着“读取”和“写入”实际上是从一块被称为缓冲区的内存区域来回复制数据。用于输出流的缓冲区只有当它写满时才会被刷新(flush 物理写入)到设备或文件中。
流分为两种类型,文本流(text)和二进制流(binary)
文本流:文本流的有些特性在不同的系统中可能不同。其中之一就是文本行的最大长度。标准规定至少允许254个字符。另一个可能不同的特性时文本行的结束方式。MS-DOS系统中,文本文件约定以一个回车符或一个换行符结尾。但是,UNIX系统只使用一个换行符结尾。标准把文本行定义为零个或多个字符,后面跟一个表示结束的换行符。
二进制流:二进制流中的字节将完全根据程序编写它们的形式写入到文件或设备中,而且完全根据它们从文件或设备读取的形式读入到程序中。
文件:stdio.h所包含的声明之一就是FILE结构。FILE是一个数据结构,用于访问一个流。如果同时激活了几个流,每个流都有一个相应的FILE与它关联。
对于每个ANSI C程序,运行时系统必须提供至少三个流——标准输入、标准输出和标准错误。这些流的名字分别为stdin、stdout和stderr,它们都是一个指向FILE结构的指针。标准输入是缺省情况下输入的来源,标准输出是缺省的输出设置。通常标准输入为键盘设备,标准输出为终端或屏幕。许多OS允许用户在程序执行时修改缺省的标准输入和输出设备。MS-DOS和UNIX系统都支持以下方法进行输入/输出的重定向。
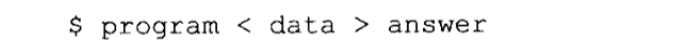
当这个程序执行时,它将从文件data而不是键盘作为标准输入进行读取,它将把标准输出写入到文件answer而不是屏幕上。
标准错误就是错误信息写入的地方。perror函数把它的输入也写到这个地方。在许多OS中,标准输出和标准错误在缺省情况下是相同的。但是,为错误信息准备一个不同的流意味着,即使标准输入重定向到其他地方,错误信息仍将出现在屏幕或其他缺省的输出设备上。
标准I/O常量。EOF是许多函数的返回值,它提示到达了文件尾。EOF所选择的实际值比一个字符要多几位,这是为了避免二进制值被错误地解释为EOF。一个程序同时最大能够打开的文件与编译器有关,但可以保证的是至少能够同时打开FOPEN_MAX个文件。这个常量包括了三个标准流,它的值至少是8。常量FILENAME_MAX是一个整型值,用于提示一个字符数组应该多大以便容纳编译器所支持的最大合法文件名。如果对文件名的长度没有一个实际的限制,那么这个常量的值就是文件名的推荐最大长度。
文件I/O的一般情况:
1.程序为必须同时处于活动状态的每个文件声明一个指针变量,其类型是FILE*。这个指针指向这个FILE结构,当它处于活动状态时由流使用。
2.流通过调用fopen函数打开。为了打开一个流,必须指定需要访问的文件或设备以及它们的访问方式(如,读、写或者即读又写)。fopen和OS验证文件或设备确实存在(有些OS中,还验证是否允许执行所指定的访问方式)并初始化FILE结构。
3.然后,根据需要对该文件进行读取或写入。
4.最后,调用fclose函数关闭流。关闭一个流可以防止与他相关联的文件被再次访问,保证任何存储于缓冲区的数据被正确地写到文件中,并且释放FILE结构使它可以用于另外的文件。
标准流I/O:标准流I/O更为简单,因为它们并不需要打开或关闭。
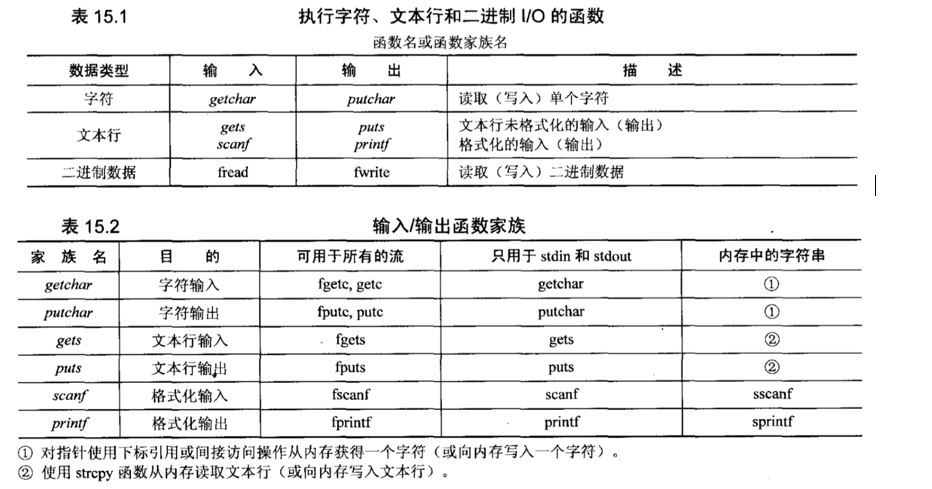
I/O函数以三种基本的形式处理数据:单个字符、文本行和二进制数据。对于每种形式,都有一组特定的函数来进行处理。每种I/O形式的函数或函数家族如下所示。函数家族以斜体表示,它指一组函数中的每个都执行相同的基本任务,只是方式稍有不同。
打开流:fopen函数打开一个特定的文件,并把一个流和这个文件相关联。函数原型如下:
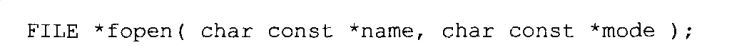
两个参数都是字符串。name是希望打开的文件或设备的名字。FILE*变量的名字是程序用来保存fopen的返回值,它并不影响那个文件被打开。mode参数提示流是用于只读、只写还是即读又写,以及它是文本流还是二进制流。常用的模式如下:

mode以r,w或a开头,分别表示打开的流用于读取、写入还是添加。在mode中添加“a+“表示该文件打开用于更新,并且流即允许读也允许写。
如果fopen函数执行成功,它返回一个指向FILE结构的指针,该结构代表这个新创建的流,如果函数执行失败,它就返回一个NULL指针。errno会提示问题的性质。
注意:应该始终检查fopen函数的返回值!如果函数失败,会返回一个NULL指针,如果程序不检查错误,这个NULL指针就会传给后续的I/O函数。它们将对这个指针执行间接访问,并将失败。
freopen函数用于打开(或重新打开)一个特定的文件流。函数原型如下:

最后一个参数就是需要打开的流。它可能是一个先前从fopen函数返回的流,也可能是标准流stdin、stdout或stder。这个函数首先试图关闭这个流,然后用指定的文件和模式重新打开这个流。如果打开失败,函数返回一个NULL的值。如果打开成功,函数就返回它的第三个参数值。
关闭流:流是用fclose关闭的,函数原型如下:
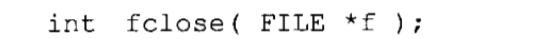
对于输入流,fclose函数在文件关闭之前刷新缓冲区。如果执行成功,fclose返回零值,否则返回EOF。
字符I/O:字符输入时由getchar函数家族执行的,它们的原型如下:

需要操作的流作为参数传递给getc和fgetc,但getchar始终从标准输入读取。每个函数从流中读取下一个字符,并把它作为函数的返回值返回。如果流中不存在更多的字符,函数就返回常量值EOF。这些函数都用于读取字符,但它们都返回一个int型值而不是char型值。原因是为了允许函数报告文件的末尾EOF。
把单个字符写入到流中,可以使用putchar函数家族。函数原型如下:

第一个参数是要被打印的字符,在打印之前,函数就把这个整数参数裁剪为一个i无符号字符型值。如果由于任何原因导致函数失败,它们就返回EOF。
字符I/O宏:fgetc和fputc都是真正的函数,但getc、putc、getchar和putchar都是通过#define指令定义的宏。
撤销字符I/O:ungetc把一个先前读入的字符返回到流中,这样它可以在以后被重新读入。函数原型如下:
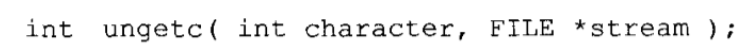
每个流都至少允许一个字符被退回,如果一个流允许退回到多个字符,那么这些字符再次被读取的顺序就以退回时的反序进行。注意把字符退回到流中和写入到流中并不相同。与一个流相关联的外部存储并不受ungetc的影响。
注意:”退回“字符和流的当前位置有关,如果用fseek、fsetpos或rewind函数改变了流的位置,所有退回的字符都将被丢弃。
未格式化的行I/O:行I/O可以用两种方式执行——未格式化或格式化。这两种形式都用于操作字符串。区别在于未格式化的I/O简单读取或写入字符串,而格式化的I/O则执行数字和其他变量的内部和外部表示形式之间的转换。gets和puts函数家族是用于操作字符串而不是单个字符。它们的函数原型如下:

fgets从指定的stream读取字符并把他们复制到buffer中。当读取到换行符并存储到缓冲区之后就不在读取。如果缓冲区内存储的字符达到了buffer_size-1个时它也停止读取。在任何一种情况下,一个NULL字节将被添加到缓冲区所存储数据的末尾,使它成为一个字符串。如果在任何字符读取前就到达了文件尾,缓冲区就未进行修改,函数返回一个NULL指针。否则,函数返回它的第一个参数(指向缓冲区的指针)。这个返回值通常用于检查是否到达了文件尾。
传递给fputs的缓冲区必须包含一个字符串,它的字符被写入到流中。该字符预期以NULL字节结尾。该字符串是逐字写入的:如果它不包含一个换行符,就不会写入换行符。如果它包含好几个换行符所有的换行符都会被写入。因此,当fgets每次都读取一整行时,fputs既可以一次写入一行的一部分,也可以一次写入一整行,甚至可以一次写入好几行。如果写入出现错误,返回常量值EOF,否则它将返回一个非负值。
注意:fget无法把字符串读入到一个长度小于两个字符的缓冲区,因为其中一个字符需要为NULL字节保留。
gets和puts函数几乎和fget和fputs相同,之所以存在它们是为了允许向后兼容。它们之间的一个主要功能区别在于当gets读取一行输入时,它并不在缓冲区存储结尾的换行符。当puts写入一个字符串时,它在字符串写入之后向输出再添加一个换行符。
格式化的行I/O:scanf家族函数原型如下:

每个原型中的省略号表示一个可变长度的指针列表。从输入转换而来的值逐个存储到这些指针参数所指向的内存位置。这些函数都从输入源读取字符并根据format字符串给出的格式代码对它们进行抓换,fscanf的输入源就是作为参数给出的流,scanf从标准输入读取,而sscanf则从第1个参数所给的字符串中读取字符。当格式化字符串到达末尾或者读取的输入不在匹配格式字符串所指定的类型时,输入停止。在任何一种情况下,被转换的输入值的数目作为函数的返回值返回。如果在任何输入值被转换之前文件就已达到尾部,函数就返回常量值EOF。
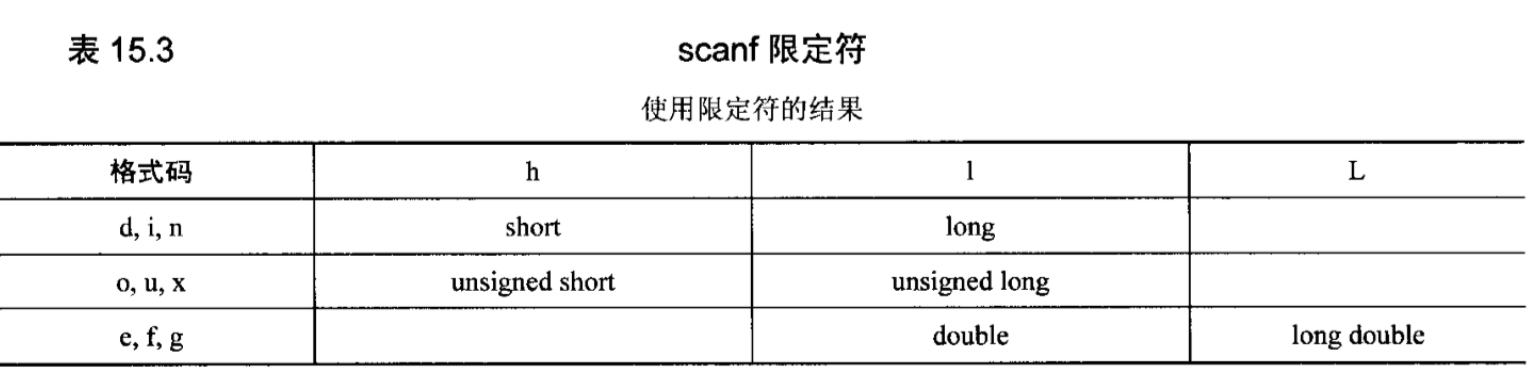
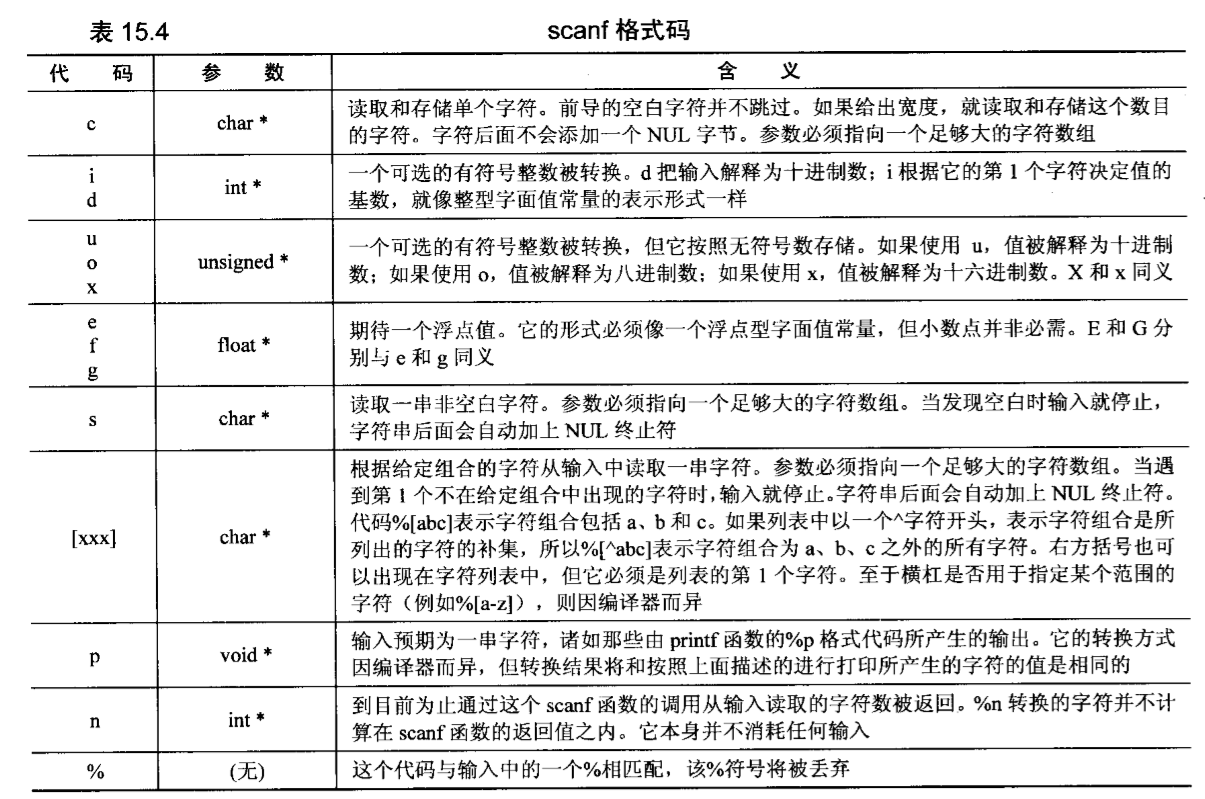
scanf函数家族中的format字符串可能包含以下内容:

scanf函数家族的格式代码都以一个百分号开头,后面可以是(1)一个可选的星号,(2)一个可选的宽度,(3)一个可选的限定符,(4)格式代码。星号将使转换后的值被丢弃而不是进行存储。宽度是一个非负的整数给出,它限制将被读取用于转换的输入字符的个数。如果省略宽度,函数就连续读入字符直到遇见输入中的下一个空白字符。限定符用于修改有些格式代码的含义。详情如下所示:
格式代码就是一个单个字符,详情如下:
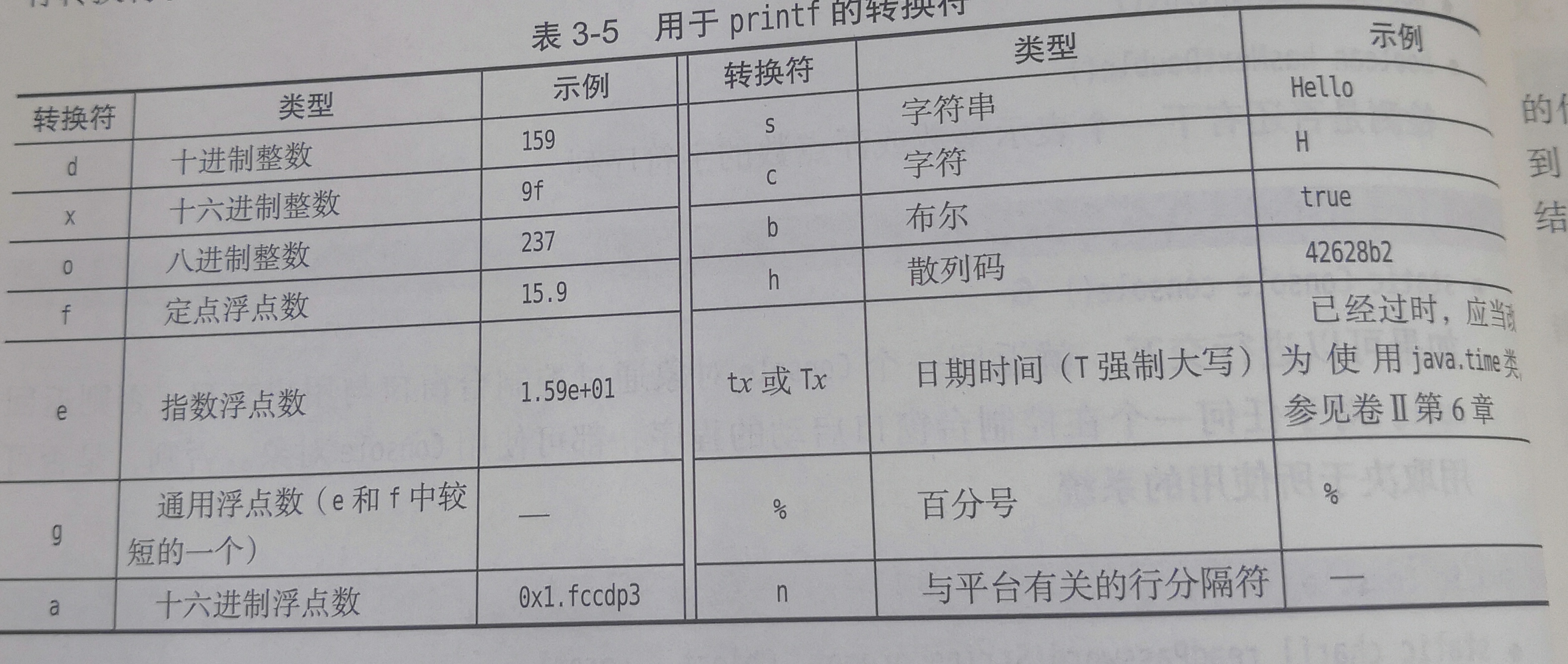
printf函数家族用于创建格式化的输入。家族函数原型如下:

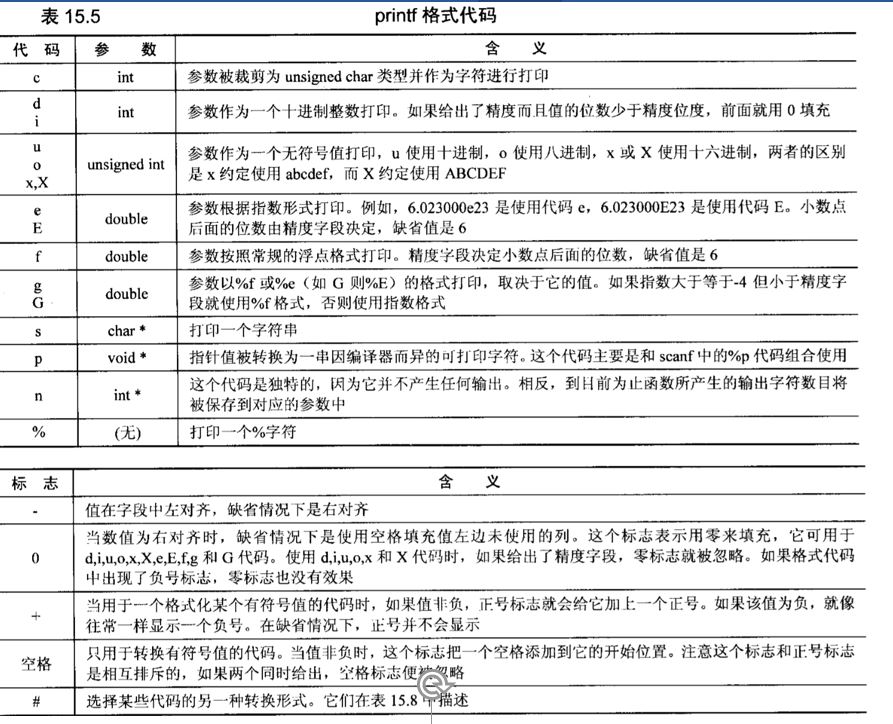
printf根据格式代码和format参数中的其他字符对参数列表中值进行格式化。使用printf结果输出到标准输出。使用fprintf,可以使用任何输出流,而sprintf把它的结果作为一个NULL结尾的字符串存储到指定的buffer缓冲区而不是写入到流中。3个函数的返回值是实际打印或存储的字符数。
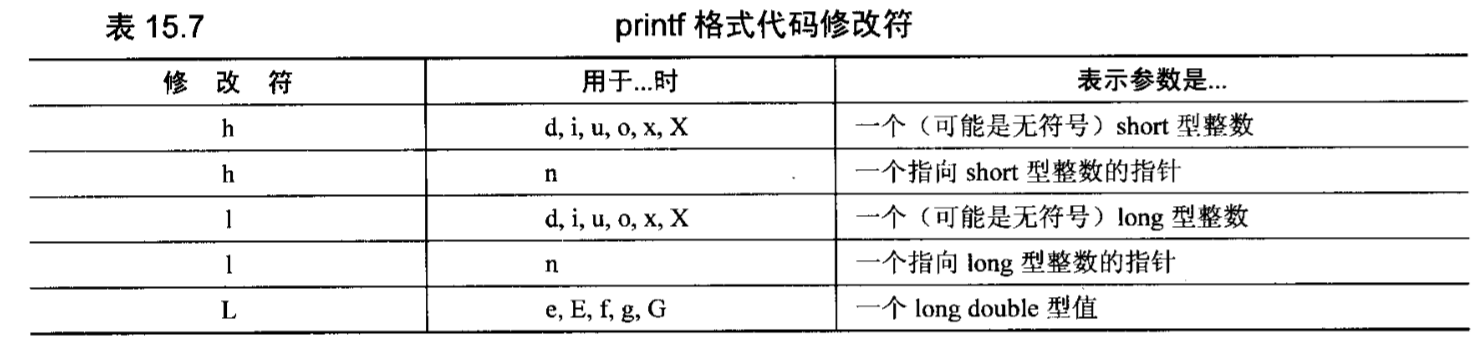
printf格式代码:格式代码由一个百分号开头,后面跟(1)零个或多个标志字符,用于修改有些转换的执行方式,(2)一个可选的最小字段宽度,(3)一个可选的精度,(4)一个可选的修改符,(5)转换类型。详情如下:
#标志可以用于几种printf格式代码,为转换选择一种替换形式。详情如下:

二进制I/O:fread函数用于读取二进制数据,fwrite函数用于写入二进制数据。函数原型如下:

buffer是一个指向用于保存数据的内存位置的指针,size是缓冲区中每个元素的字节数,count是读取或写入的元素数,stream是数据读取或写入的流。buffer参数被解释为一个或多个值的数组。count参数指定数组中有多少个值。函数的返回值是实际读取或写入的元素(并非字节)数目。如果输入过程遇到了文件尾或者输出过程中出现了错误,这个数字可能比请求的元素数目要小。
刷新和定位函数。fflush函数迫使一个输出流的缓冲区内的的数据进行物理写入,不管它是不是已经写满。函数原型如下:
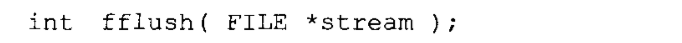
在正常情况下,数据以线性的方式写入。同时C也支持随机访问I/O,也就是以任意顺序访问文件的不同位置。随机访问是通过在读取或写入先前定位到文件中需要的位置来实现的。有两个函数用于执行该项操作,函数原型如下:

ftell函数返回流的当前位置,也就是说,下一个读取或写入将要开始的位置距离文件起始位置的偏移量。在二进制流中,这个值是当前位置距离文件起始位置之间的字节数。在文本流中,这个值表示一个位置,但因为OS原因它不一定准确地表示当前位置和文件起始位置之间的字节数。但是ftell函数返回的值总是可以用于fseek函数中,作为一个距离文件起始位置的偏移量。
fseek函数允许在一个流中定位。它的第1个参数是需要改变的流,第2和第3个参数标识文件需要定位的位置。详情如下:

在二进制中从SEEK_END进行定位可能不被支持,所以应该避免。在文本流中,如果from是SEEK_CUR或SEEK_END,offset必须是零。如果from是SEEK_SET,offset必须是一个从同一个流中以前调用ftell所返回的值。
用fseek改变一个流的位置会带来三个副作用。首先,行末指示字符被清除。其次,如果在fseek之前使用ungetc把一个字符返回到流中,那么这个被退回的字符会被丢弃,因为在定位操作以后,它不再是”下一个字符“。最后,定位允许你从写入模式切换到读取模式,或者回到打开的流以便更新。
另外还有三个额外的函数,用一些限制更严的方式执行相同的任务。函数原型如下:

rewind函数将读/写指针设置回指定流的起始位置,同时清除流的错误提示标识。fgetpos和fsetpos分别是ftell和fseek函数的替代方案。它们的主要区别在于这对函数接受一个指向fpost_t的指针作为参数。fgetpos在这个位置存储文件的当前位置,fsetpos把文件位置设置为存储在这个位置的值。
改变缓冲方式:下面两个函数可用于对缓冲方式进行修改。这两个函数只有当指定的流被打开但还没有在它上面执行其他操作前才能被调用。函数原型如下:
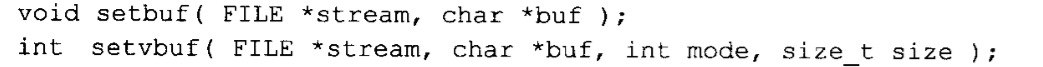
setbuf设置了另一个数组,用于对流进行缓冲。该数组的字符长度必须为BUFSIZ (它在stdio.h中定义)。为一个流自行指定缓冲区可以防止 I/O函数库为它动态分配一个缓冲区。如果用一个NULL参数调用该函数,setbuf函数将关闭流的所有缓存方式。字符准确地将程序所规引的方式进行读取和写入。
setvbuf函数更为通用。mode参数用于指定缓冲的类型。_IOFBF指定一个完全缓冲的流,_IONBF指定一个不缓冲的流,_IOLBF指定一个行缓冲流。所谓行缓冲流,就是每当一个换行符写入到缓冲区时,缓冲区便进行刷新。buf和size参数用于指定需要使用的缓冲区。如果buf为NULL,那么size的值必须是0,一般而言,最好用一个长度为BUFSIZ的字符数组作为缓冲区。
流错误函数:函数原型如下:

如果流当前处于文件尾,feof函数返回真。该状态可以通过对流执行fseek,rewind或fsetpos函数来清除。ferro函数报告流的错误状态,如果出现任何读/写错误函数就返回真。最后cleareer函数对指定的错误标志进行重置。
临时文件:tempfile函数用于创建一个临时文件,当文件被关闭或程序终止时这个文件便自动删除,该文件以wb+模式打开,这使它可以用于二进制和文本数据。函数原型如下:
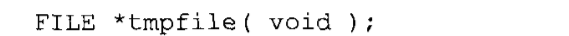
临时文件的名字可以用tmpnam函数创建,函数原型如下:
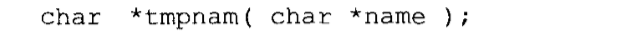
如果传递给函数的参数为NULL,那么这个函数便返回一个指向静态数组的指针,该数组包含了被创建的文件名。否则,参数便假定是一个指向长度至少为L_tmpnam的字符数组的指针。在这种情况下,文件名在这个数组中创建,返回值就是这个参数。无论哪种情况,这个被创建的文件名保证不会与存在的文件名同名。只有调用次数不超过TMP_MAX次,tmpnam函数每次调用时都能产生一个新的不同名字。
文件操作函数:有两个函数用于操作文件但不执行任何输入/输出操作。两个函数如果执行成功,返回零值。如果失败,返回非零值。函数原型如下:

remove函数删除一个指定的文件。如果函数被调用时文件正处于打开状态,其结果将取决于编译器。
rename函数用于改变一个文件的名字,从oldname改为newname。如果已经有一个名为newname的文件存在,其结果将取决于编译器。如果函数失败,文件仍然可以用原来的名字进行访问。










































 之间的一个弧度。acos的返回值是一个范围在0和
之间的一个弧度。acos的返回值是一个范围在0和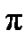 之间的一个弧度。最后一个函数返回表达式y/x的反正切值,但它使用这个参数的符号来决定结果值位于那个象限。它的返回值是一个范围在
之间的一个弧度。最后一个函数返回表达式y/x的反正切值,但它使用这个参数的符号来决定结果值位于那个象限。它的返回值是一个范围在 之间的弧度。
之间的弧度。


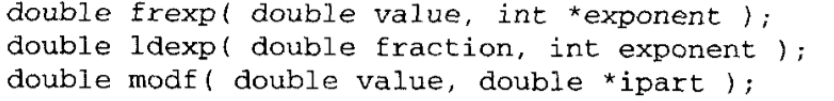
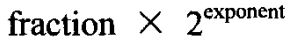 =value。其中0.5<=fraction<1,exponent是一个i整数。exponent存储于第2个参数所指向的内存位置。函数返回fraction的值。第二个函数的返回值是
=value。其中0.5<=fraction<1,exponent是一个i整数。exponent存储于第2个参数所指向的内存位置。函数返回fraction的值。第二个函数的返回值是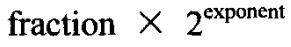 也就是它原型的值。最后一个函数把一个浮点值分成整数和小数两个部分,每个部分都具有和原值一样的符号。整数部分以double类型存储于第2个参数所指向的内存位置,小数部分作为函数的返回值返回。
也就是它原型的值。最后一个函数把一个浮点值分成整数和小数两个部分,每个部分都具有和原值一样的符号。整数部分以double类型存储于第2个参数所指向的内存位置,小数部分作为函数的返回值返回。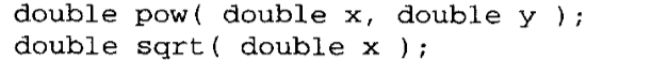
 的值。由于在计算这个值时可能要用到对数,所以如果x是一个负数且y不是一个整数,就会出现一个定义域错误。第二个函数返回其参数的平方根。如果参数为负,就会出现一个定义域错误。
的值。由于在计算这个值时可能要用到对数,所以如果x是一个负数且y不是一个整数,就会出现一个定义域错误。第二个函数返回其参数的平方根。如果参数为负,就会出现一个定义域错误。