环境:在ANSI C的任何一种实现中,存在两种不同的环境。第1种翻译环境(translation environment),在这个环境里源代码被转换为可执行的机器指令。第2种是执行环境(execution environment),它用于实际执行代码。
翻译:组成一个程序的每个(或是多个)源文件通过编译过程分别转换为目标代码,然后各个文件由链接器(linker)捆绑在一起,形成一个单一而完整的可执行程序。链接器同时也会引入标准C函数库中任何被程序所用到的函数。
编译:编译过程本身也由几个阶段完成。第一步是预处理器(preprocessor)处理,第二步是源代码解析,第三步便是产生目标代码。目标代码是机器指令的初步形式,用于实现程序的语句。如果在编译程序的命令行中加入了要求进行优化的选项,优化器(optimizer)就会对目标代码进一步进行处理,使它效率更高。编译过程如下所示:
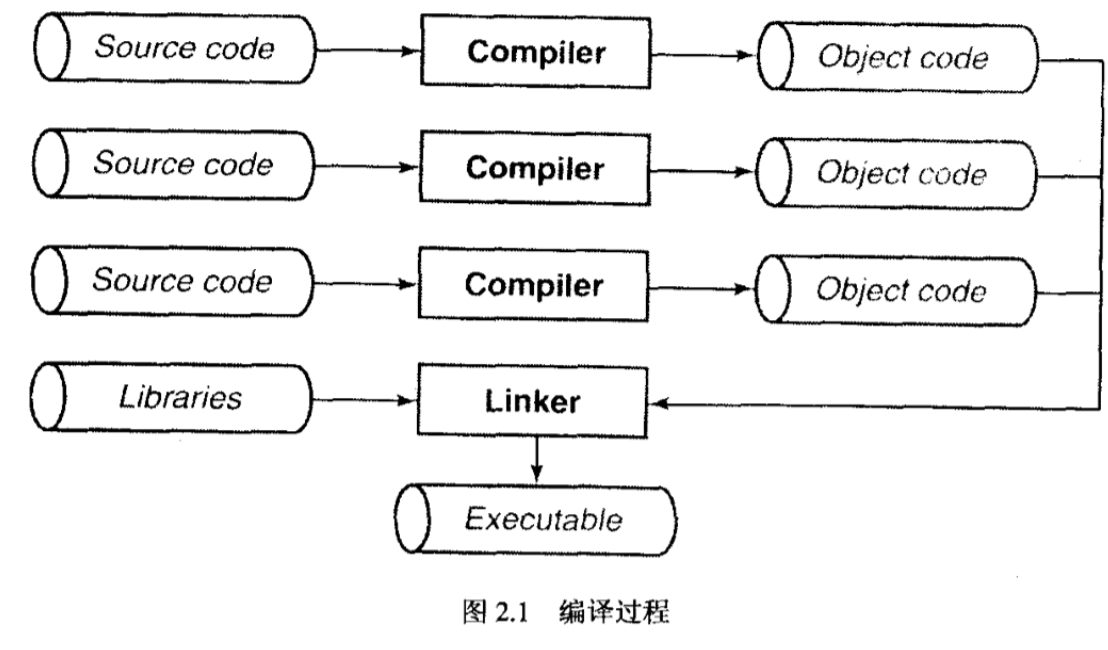
文件名约定:C源代码通常保存于以.c扩展名命名的文件中。由#include指令包含到C源代码的文件被称为头文件通常具有扩展名.h。目标文件名在不同的环境中可能具有不同的约定。如在UNIX系统中扩展名为.o,但是MS-DOS系统中扩展名为.obj。
编译和链接:在大多数的UNIX系统中,C编译器被称为cc,它可以用多种不同的方法来调用。
执行:程序的执行过程也需要经历几个阶段。首先,程序必须载入到内存中,然后程序的执行便开始。在大多数机器里,程序将使用一个运行时堆栈(stack),它用于存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储于静态内存的变量在程序的整个执行过程中将一直保留它们的值。程序执行的最后一个阶段就是程序的终止,它可以由多种不同的原因引起。
词法规则:一个ANSI C程序由声明和函数组成。函数定义了需要执行的工作,而声明则描述了函数和(或)函数将要操作的数据类型(有时候是数据本身)。注释可以散步于源文件的各个地方。
字符:标准并没有规定C环境必须使用哪种特定的字符集,但它规定字符集必须包括英语所有的大写和小写字母,数字0到9,以及如下这些符号:
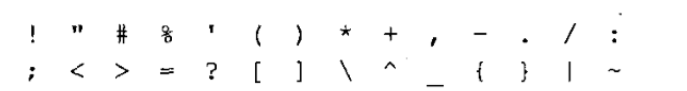
换行符用于标识源代码每一行的结束。标识还定义了几个三字母词(trigrph),三字母词就是几个字符的序列合起来表示另一个字符。如下是一些三字母词以及它们所代表的字符:

K&R C定义了几个转义序列(escape sequence)或字符转义(character escape),ANSI C在它的基础上又增加了几个转义序列。转义序列由一个反斜杠\加上一或多个其他字符组成。如下列出了部分:

标识符:标识符(identifier)就是变量,函数,类型等的名字。它们由大小写字母、数字和下划线组成,但不能以数字开头。C区分大小写。标识符的长度没有限制,但标准允许编译器忽略第31个字符以后的字符,标准同时允许编译器对用于表示外部名字(也就是由链接器操作的名字)的标识符进行限制,只识别前六位不区分大小写的字符。

程序的形式:一个C程序可能保存于一个或多个源文件中,虽然一个源文件可以包含超过一个的函数,但每个函数都必须完整的出现于同一个源文件中