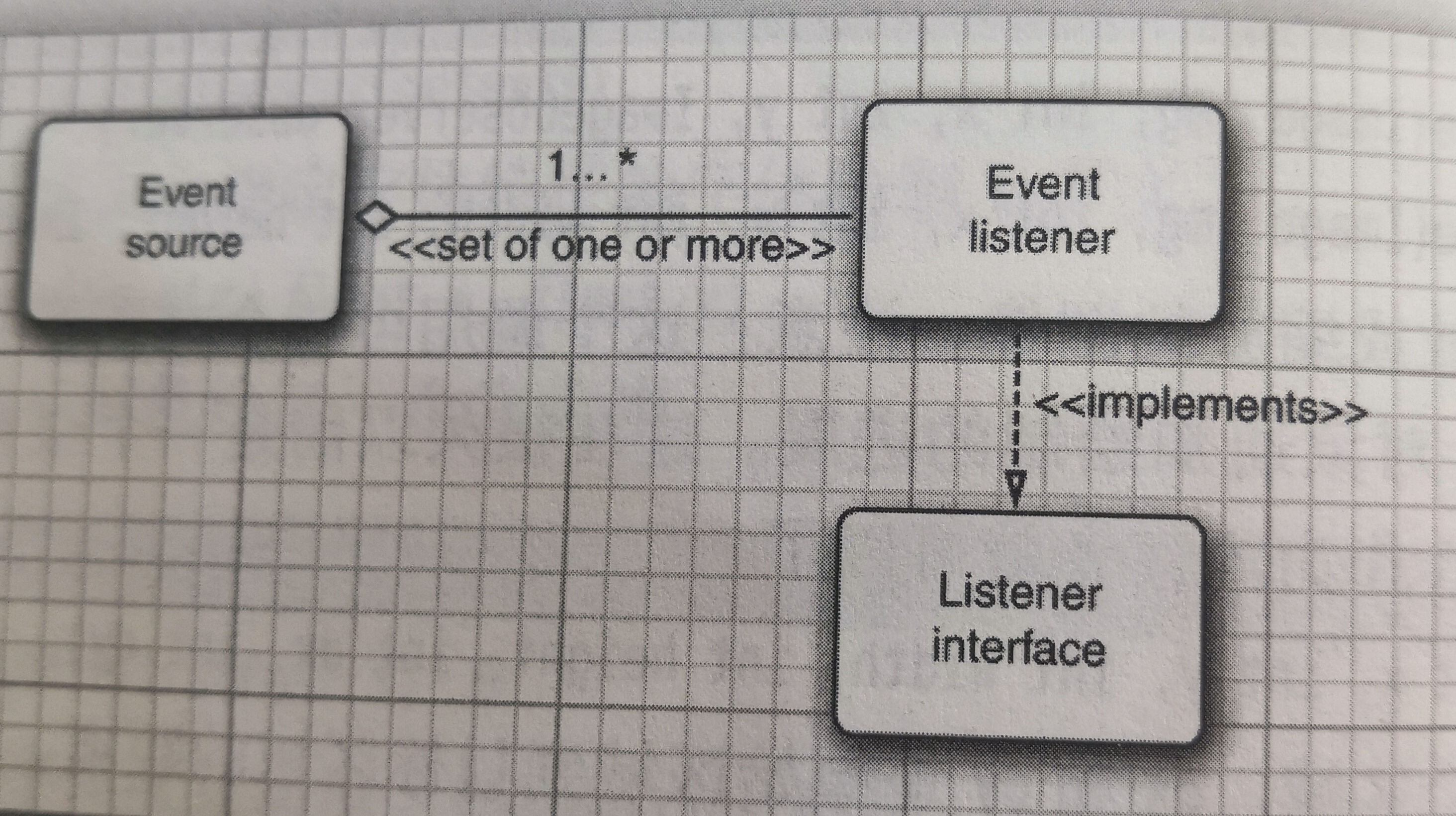
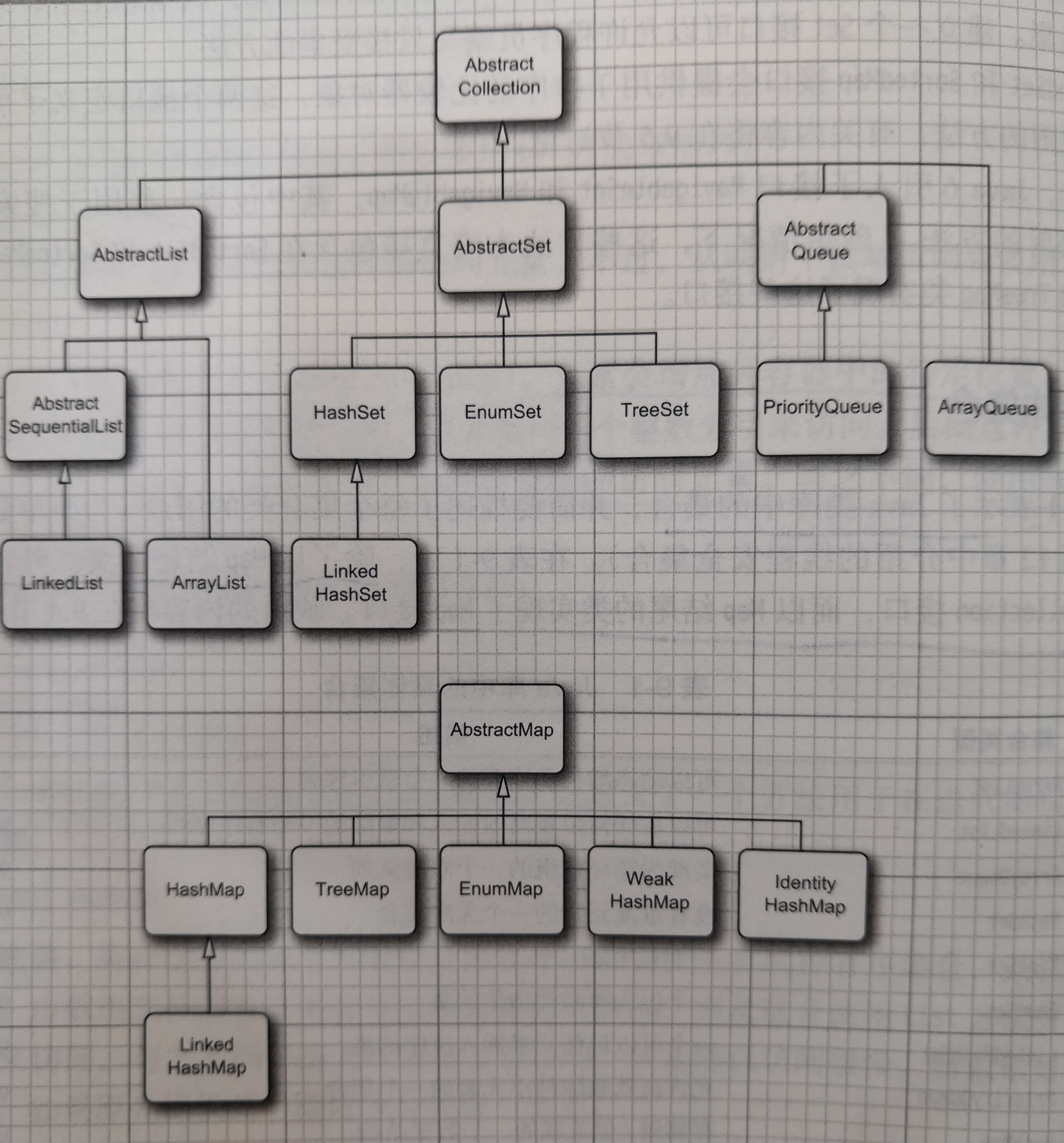
多任务是OS的一种能力,看起来可以在同一时刻运行多个程序。多线程程序在更低一层扩展了多任务的概念:单个程序看起来在同时完成多个任务。每个任务在一个线程(thread)中执行,线程是控制线程的简称。如果一个程序可以同时运行多个线程,则称这个线程是多线程的(multi threaded)。
多进程与多线程的区别在于每个进程拥有自己的一整套变量,而线程则共享数据。Java中用于创建和启动的线程的几个基础方法的API如下:

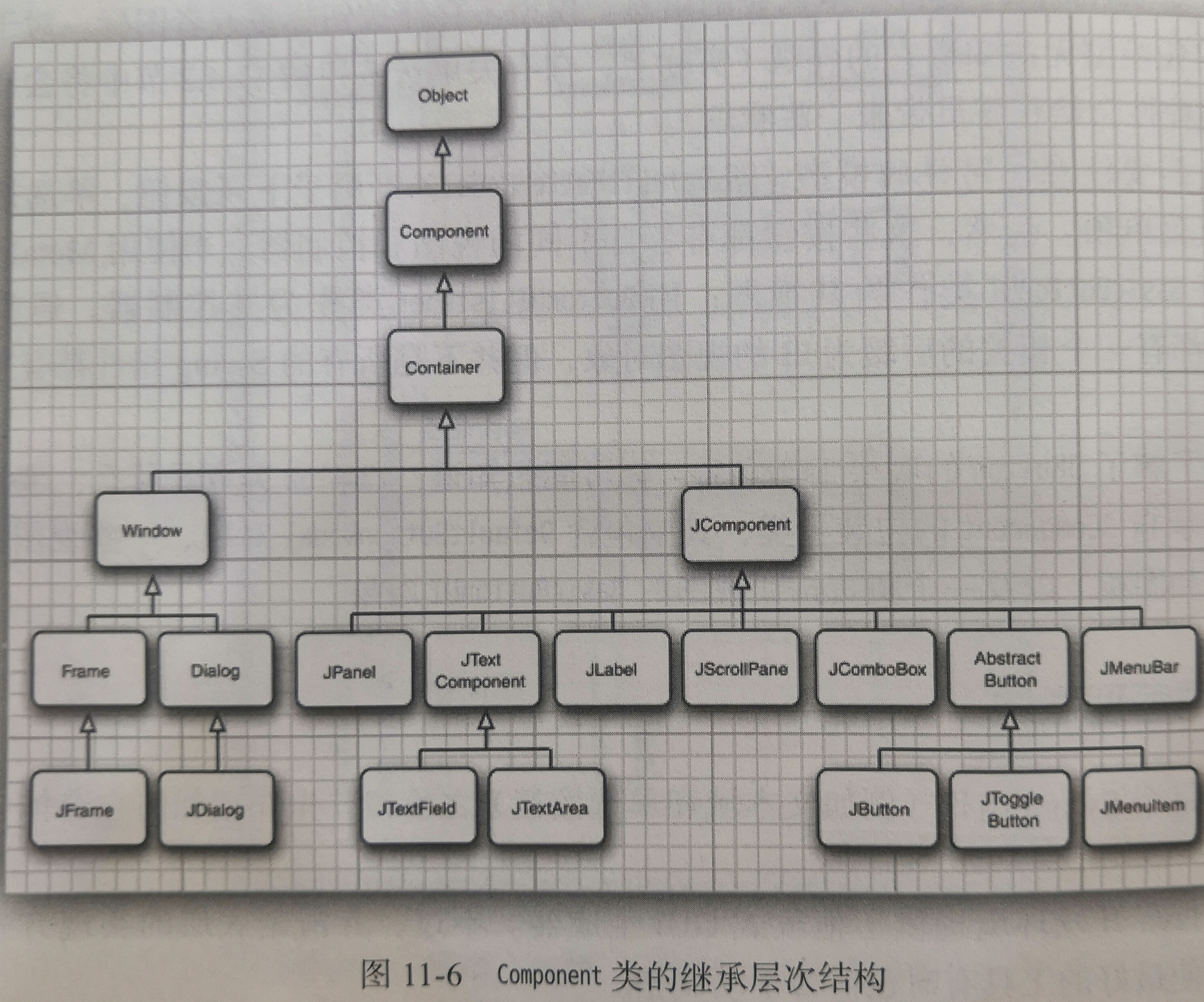
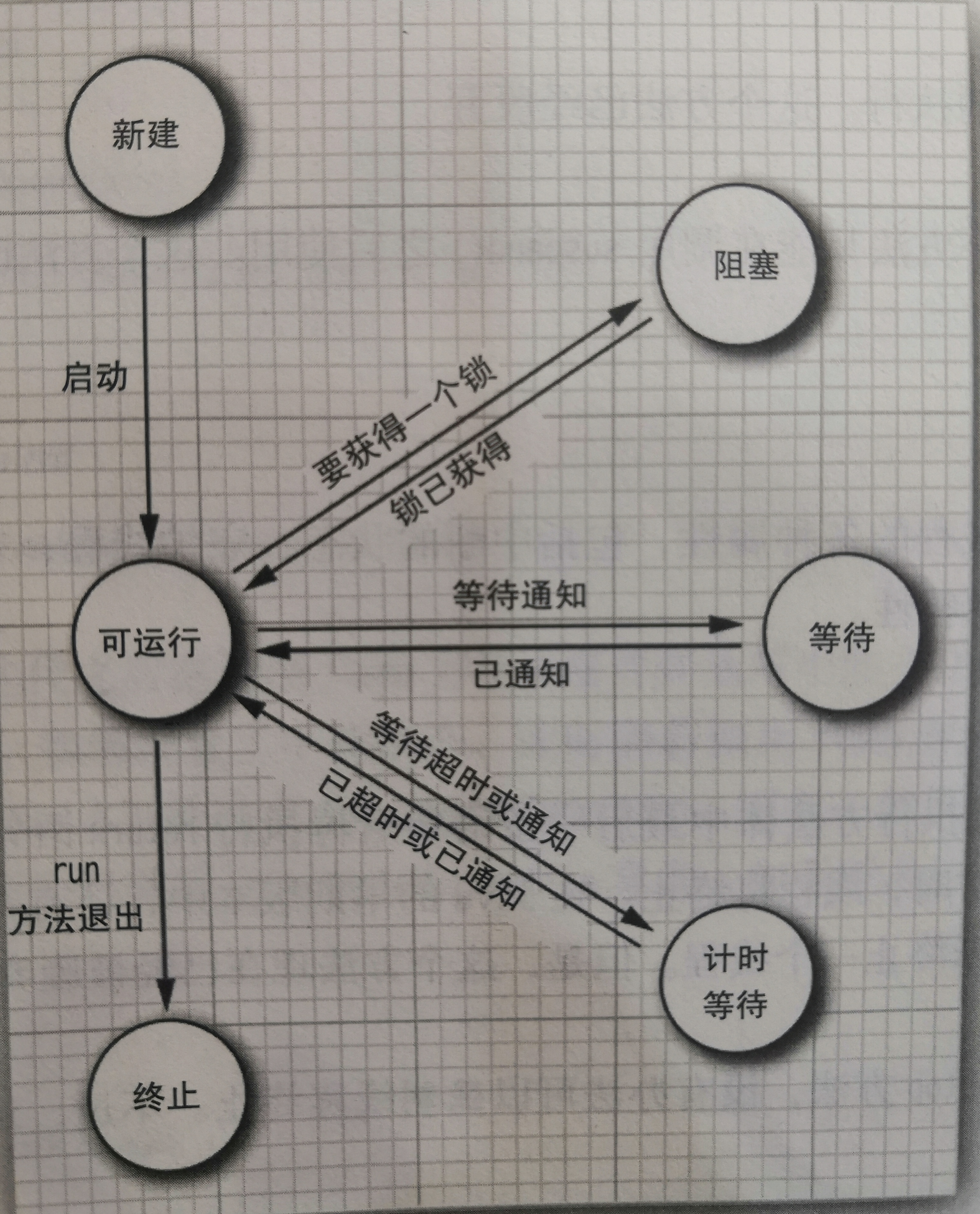
线程可以有6种状态:New(新建)、Runnable(可运行)、Blocked(阻塞)、Waiting(等待)、Timed waiting(计时等待)、Terminated(终止)。当确定一个线程的当前状态时,可以调用getState方法。
New(新建):用new操作符创建一个新的线程。当一个线程处于新建状态时,程序还没有开始运行线程中的代码。
Runnable(可运行):当调用start方法时,线程就处于可运行(runnable)状态。一个可运行的线程可能正在运行也可能没有运行。要由OS为线程提供具体的运行时间。因为Java规范没有将正在运行作为一个单独的状态,所以一个正在运行的线程仍然处于可运行状态。要记住,在任何给定时刻,一个可运行的线程可能正在运行也可能没有运行(正式因为这样,该状态称为“可运行”而不是“运行”)。
Blocked(阻塞):当一个线程试图获取一个内部的对象锁,而这个锁目前被其他线程占有,那么该线程就会被阻塞。当所有其他线程都释放了这个锁,并且线程调度器运行该线程持有这个锁时,它将变成非阻塞状态。
Waiting(等待):当线程等待另一个线程通知调度器出现一个条件时,这个线程会进入等待状态。实际上,阻塞状态与等待状态没有太大区别。
Timed waiting(计时等待):Java中,有几个方法有超时参数,调用这些方法会让线程进入计时等待状态。这一状态将一直保持到超时期满或者接收到适当的通知。
Terminated(终止):线程会因为两个原因而终止。第一,run方法正常退出,线程自然终止。第二,因为一个没有捕获的异常终止了run方法,使线程意外终止。如下展示了线程可能的状态以及从一个状态到另一个可能的转换。
Java的早期版本中有一个stop方法可以用来终止线程,但现在该方法已被废弃了。处理stop方法外,interrupt方法也可以用来请求终止一个线程。当线程调用interrupt方法时,就会设置线程的中断状态。这是每个线程都有的boolean标志。每个线程都应该不时地检查这个标志,以判断线程是否被中断。但是,如果线程被阻塞,就无法检查中断状态。有关中断线程的方法API如下:


可以通过setDaemon方法将一个线程转换为守护线程。该方法的API如下所示。守护线程的唯一用途是为其他线程提供服务。当只剩下守护线程时,虚拟机就会退出,因为如果只剩下守护线程,就没必要继续运行程序了。

可以使用setName方法为线程设置任何名字。线程的run方法不能抛出任何检查型异常,但是,非检查型异常可能会导致线程终止。在这种情况下,线程会死亡。在线程死亡之前,异常会传递到一个用于处理未捕获异常的处理器。这个处理器必须属于一个实现了Thread.UncaughtExecptionHandler接口的类。可以用setUncaughtExecptionHandler方法为任何线程安装一个处理器。也可以用Thread类的静态方法setDefaultUncaughtExecptionHandler为所有线程安装一个默认的处理器。如果没有安装默认处理器,默认处理器则为null。但是,如果没有为单个线程安装处理器,那么处理器就是该线程的ThreadGroup对象。线程组是可以一起管理的线程的集合。默认情况下,创建的所有线程都属于同一个线程组,但是也可以建立其他的组。上述方法的API如下:

Java中,每一个线程有一个优先级。默认情况下,一个线程会继承构造它的那个线程的优先级。每当线程调度器有机会选择新线程时,它首先选择具有较高优先级的线程。但是,线程的优先级高度依赖于系统。有关设置线程优先级的方法API如下:

当两个线程存取同一个对象,并且每个线程分别调用了一个修改该对象状态的方法。这时两个线程回互相覆盖,取决于线程访问数据的次序,可能会导致对象被破坏。这种情况被称为竟态条件。Java 5引入了ReentrantLockle类用来保护代码块以防止并发地访问代码块。它的基本结构如下:

这个结构确保任何时刻只有一个线程进入临界区。一旦一个线程锁定了锁对象,其他任何线程都无法通过lock语句。当其他线程调用lock时,它们会暂停,直到第一个线程释放这个锁对象。要把unlock操作包括在finally子句中,这一点非常重要。万一在临界区的代码抛出一个异常,锁必须释放。否则,其他线程将永远阻塞。这个锁称为重入(reentrant)锁,因为线程可以反复获得已拥有的锁。锁有一个持有计数来跟踪对lock方法的嵌套调用。线程每一次调用lock后都要调用unlock来释放锁。由于这个特性,被一个锁保护的代码可以调用另一个使用相同锁的方法。要注意确保临界区中的代码不要因为抛出异常而跳出临界区。如果在临界区代码结束之前抛出了异常,finally子句将释放锁,但是对象可能处于被破坏的状态。相关方法的API如下:

可以使用一个条件对象(条件变量)来管理那些已经获得了一个锁却不能做有用工作的线程。一个锁可以有一个或多个相关联的条件对象。可以用newCondition方法获得一个条件对象。死锁现象是指当所有其他线程都被阻塞,最后一个活动线程调用了await方法但没有先解除另外某个线程的阻塞,因为最后一个活动线程也阻塞了,此时没有线程可以解除其他线程的阻塞状态,程序便会永远挂起。相关方法的API如下:

从1.0版本开始,Java中的每个对象都有一个内部锁。如果一个方法声明时有synchronized关键字,那么对象的锁将保护整个方法。也就是说,要调用这个方法,线程必须获得内部对象锁。内部对象锁只有一个关联条件。wait方法将一个线程增加到等待集中,notifyAll/notify方法可以解除等待线程的阻塞。除此之外,还可以使用synchronized声明一个代码块使之成为同步块。进入一个同步块,一样可以获得锁。Java虚拟机对同步方法提供了内置支持。不过,同步块会编译为很长的字节码序列来管理内部锁。相关方法的API如下:

出与锁和条件不是面向对象的原因的,20世纪70年代Per Brinch Hansen和Tony Hoare提出了一种面向对象的概念使其用于同步,那就是监视器。用Java术语来讲,监视器具有如下特性:
1)监视器是只包含私有字段的类。
2)监视器类的每个对象有一个关联的锁。
3)所有方法由这个锁锁定。
4)锁可以有任意多个相关联的条件。
volatile关键字为实例字段的同步访问提供了一种免锁机制。如果声明一个字段为volatile,那么编译器和虚拟机就知道该字段可能被另一个线程并发更新。volatile变量不能提供原子性。
可以使用ThreadLocal辅助类为各个线程提供了各自的实例。常用方法的API如下:

阻塞队列是一个在协调多个线程之间合作时的一个工具。工作线程可以周期性地将中间结果存储在阻塞队列中。其他工作线程移除中间结果,并进一步进行修改。队列会自动平衡负载。下表显示是阻塞队列的方法:
java.util.concurrent包提供了阻塞队列的几个变体。相关的API如下:


java.util.concurrent包同时也提供了映射、有序集和队列的高效实现。相关的API如下:


Java API为并发散列映射提供了批操作,即使有其他线程在处理映射,这些操作也能安全地执行。有3中不同的操作:
1)search(搜索)为每个键或值应用一个函数,直到函数生成一个非null的结果。然后搜索终止,返回这个函数的结果。
2)reduce(归约)组合所有键或值,这里要使用所提供的一个累加函数。
3)forEach为所有键或值应用一个函数。
每个操作都有4个版本:operationKeys:处理键;operationValues:处理值;operation:处理键和值;operationEntries:处理Map.Entry对象。对于上述各个操作,需要指定一个参数化阈值。如果映射包含的元素多余这个阈值,就会并行完成批操作。如果希望批操作在一个线程中运行,可以使用阈值Long.MAX_VALUE。如果希望用尽可能多的线程运行批操作,可以使用阈值1。